Situations arise where logical data generation becomes a requirement. By 'Logical Data Generation', I mean generating additional data based on a logic being applied to existing data. Of course, there are multiple ways of doing the same. In this article, I would like to demonstrate how it conventionally being done using cursors and how it can be done much more efficiently using CTE's. The concept is being brought out using a simple example.
The problem:
In order to explain the problem, let me first create two tables, dbo.abc and dbo.def. Once we get familiarity with the data, it would be easier to explain the problem. The table dbo.abc has four columns namely, SeqNo, Date_Field, Month_Count, and Payment. Lets create and populate it by executing the code below:
if exists (select * from sys.tables
where name = 'abc'
and USER_NAME(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.abc
go
create table dbo.abc
(SeqNo smallint
,Date_Field datetime
,Month_Count tinyint
,Payment decimal(10,2))
go
insert into dbo.abc (SeqNo, Date_Field, Month_Count, Payment)
values (1, '20090101', 10, 100)
,(2, '20100101', 7, 200)
,(3, '20110101', 5, 300)
go
Lets create another table dbo.DEF with the columns SeqNo, Date_Field, and Payment only. We will keep it empty for now.
if exists (select * from sys.tables
where name = 'def'
and USER_NAME(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.def
go
create table dbo.def
(SeqNo smallint
,Date_Field datetime
,Payment decimal(10,2))
go
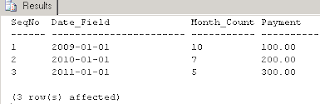
Please execute the code below to view the data in the table, dbo.abc:
select * from abc
go
The lets define the problem. Each row in the table, dbo.abc has to be duplicated as many times as the value of Month_Count in that row. Currently the Date_Field has a value that represents the first day of an year. While duplicating the data, we need to ensure that each new row has its Date_Field value incremented by one month. We need to stop the duplication as soon as we reach the month value in the column Month_Count for that row. The values for the columns SeqNo and Payment should remain as they are in the original row. This process needs to be done for all rows in the table, dbo.abc. Finally we need to display all the original and duplicated rows.
Now let us write a conventional SQL Server 2000 type program. Since I have to loop through the data in each row, I am ending up using a CURSOR and a WHILE loop. The T-SQL program is given below:
declare @l_SeqNo int
,@l_date_field datetime
,@l_Month_Count smallint
,@l_Payment decimal(10, 2)
,@l_counter smallint
select @l_counter = 0
set nocount on;
declare i_Cursor insensitive cursor
for
select SeqNo, Date_Field, Month_Count, Payment from dbo.abc
open i_Cursor
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
while @@fetch_status = 0
begin
select @l_counter = 0
while (@l_counter < @l_Month_Count)
begin
insert into dbo.def (SeqNo, Date_Field, Payment)
select @l_SeqNo, dateadd(mm, @l_counter, @l_date_field), @l_Payment
select @l_counter = @l_counter + 1
end
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
end
close i_Cursor
deallocate i_Cursor
set nocount off;
go
After executing the above program, let us check the table dbo.DEF:
select * from def

It may be noted in the result set above that the row with SeqNo 1 has been duplicated 10 times, 10 being the value of the Month_Count field in table dbo.abc. Similarly, the row with SeqNo 2 has been duplicated 7 times, 7 being the value of the Month_Count field in table dbo.abc. Finally the row with SeqNo 3 in the table dbo.abc has been duplicated 5 times, 5 being the value of the Month_Count field in table dbo.abc. We have kept the values of SeqNo and Payment columns intact through this duplication exercise.
The problem has been solved. Now let us solve the same problem in a different way using Recursive CTE in SQL Server 2005/2008 style of coding. The code is given below. please execute the same:
with CTE_Base (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency)
as
(select SeqNo, Date_Field, Month_Count, Payment, Date_Field, dateadd(mm, Month_Count-1, Date_Field), 1 from abc)
,CTE_Level1 (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency)
as
(select SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency from CTE_Base
union all
select SeqNo, dateadd(mm, Frequency, Date_Field), Month_Count, Payment, Begin_Date, End_Date, Frequency
from CTE_Level1
where dateadd(mm, Frequency, Date_Field) between Begin_Date and End_Date)
select SeqNo, Date_Field, Payment
from CTE_Level1
where Date_Field between Begin_Date and End_Date
order by SeqNo, Date_Field
go
Here is the result set:

The problem:
In order to explain the problem, let me first create two tables, dbo.abc and dbo.def. Once we get familiarity with the data, it would be easier to explain the problem. The table dbo.abc has four columns namely, SeqNo, Date_Field, Month_Count, and Payment. Lets create and populate it by executing the code below:
if exists (select * from sys.tables
where name = 'abc'
and USER_NAME(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.abc
go
create table dbo.abc
(SeqNo smallint
,Date_Field datetime
,Month_Count tinyint
,Payment decimal(10,2))
go
insert into dbo.abc (SeqNo, Date_Field, Month_Count, Payment)
values (1, '20090101', 10, 100)
,(2, '20100101', 7, 200)
,(3, '20110101', 5, 300)
go
Lets create another table dbo.DEF with the columns SeqNo, Date_Field, and Payment only. We will keep it empty for now.
if exists (select * from sys.tables
where name = 'def'
and USER_NAME(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.def
go
create table dbo.def
(SeqNo smallint
,Date_Field datetime
,Payment decimal(10,2))
go
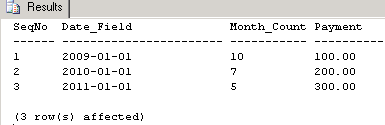
Please execute the code below to view the data in the table, dbo.abc:
select * from abc
go
The lets define the problem. Each row in the table, dbo.abc has to be duplicated as many times as the value of Month_Count in that row. Currently the Date_Field has a value that represents the first day of an year. While duplicating the data, we need to ensure that each new row has its Date_Field value incremented by one month. We need to stop the duplication as soon as we reach the month value in the column Month_Count for that row. The values for the columns SeqNo and Payment should remain as they are in the original row. This process needs to be done for all rows in the table, dbo.abc. Finally we need to display all the original and duplicated rows.
Now let us write a conventional SQL Server 2000 type program. Since I have to loop through the data in each row, I am ending up using a CURSOR and a WHILE loop. The T-SQL program is given below:
declare @l_SeqNo int
,@l_date_field datetime
,@l_Month_Count smallint
,@l_Payment decimal(10, 2)
,@l_counter smallint
select @l_counter = 0
set nocount on;
declare i_Cursor insensitive cursor
for
select SeqNo, Date_Field, Month_Count, Payment from dbo.abc
open i_Cursor
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
while @@fetch_status = 0
begin
select @l_counter = 0
while (@l_counter < @l_Month_Count)
begin
insert into dbo.def (SeqNo, Date_Field, Payment)
select @l_SeqNo, dateadd(mm, @l_counter, @l_date_field), @l_Payment
select @l_counter = @l_counter + 1
end
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
end
close i_Cursor
deallocate i_Cursor
set nocount off;
go
After executing the above program, let us check the table dbo.DEF:
select * from def

It may be noted in the result set above that the row with SeqNo 1 has been duplicated 10 times, 10 being the value of the Month_Count field in table dbo.abc. Similarly, the row with SeqNo 2 has been duplicated 7 times, 7 being the value of the Month_Count field in table dbo.abc. Finally the row with SeqNo 3 in the table dbo.abc has been duplicated 5 times, 5 being the value of the Month_Count field in table dbo.abc. We have kept the values of SeqNo and Payment columns intact through this duplication exercise.
The problem has been solved. Now let us solve the same problem in a different way using Recursive CTE in SQL Server 2005/2008 style of coding. The code is given below. please execute the same:
with CTE_Base (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency)
as
(select SeqNo, Date_Field, Month_Count, Payment, Date_Field, dateadd(mm, Month_Count-1, Date_Field), 1 from abc)
,CTE_Level1 (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency)
as
(select SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency from CTE_Base
union all
select SeqNo, dateadd(mm, Frequency, Date_Field), Month_Count, Payment, Begin_Date, End_Date, Frequency
from CTE_Level1
where dateadd(mm, Frequency, Date_Field) between Begin_Date and End_Date)
select SeqNo, Date_Field, Payment
from CTE_Level1
where Date_Field between Begin_Date and End_Date
order by SeqNo, Date_Field
go
Here is the result set:

If we set "Show Actual Execution Plan" and then run both the queries (the cursor based one and the recursive CTE based one), you will note that the query cost of the conventional cursor based approach to this problem's solution is 94% where as it is 6% with the recursive CTE based solution.
It may also be noted that in the recursive CTE not a single variable has been used unlike the cursor based methodology.
The problem I have used in this article is just to solve a situation where new data is to be generated based on applying certain logic on existing data. In practice, there are and would be many more such situations where recursive CTE's can be put to good use for efficieny in execution and brevity of code.